Navegación por voz: Accesibilidad en la web
Uno de los mayores retos de la sociedad de la información hoy en día es dotar de accesibilidad a personas discapacitadas, eliminando las barreras que pudiesen encontrar. En la tarea de navegación por internet, las personas que tuviesen dificultad para manejar el ratón o teclado de un ordenador, necesitarían de ayuda de otra persona. Por ello, un sistema de navegación por voz posibilitaría el acceso a los medios de internet de forma autónoma, facilitando la accesibilidad.
Hoy en día, el estado de la tecnología de reconocimiento y síntesis del habla permite utilizar la voz en aplicaciones "simples" de comando y control. Un ejemplo de aplicación es la navegación por voz que permite mejorar la accesibilidad de a las páginas web.
Entendemos por navegación por voz la utilización tanto de un sistema de reconocimiento de voz para la navegación a través de las páginas web como la conversión texto-voz para la lectura de textos escritos en la página web.
La I+D+i en Tecnologías del Habla es la línea prioritaria del laboratorio ViVoLab del Grupo de Tecnologías de las Comunicaciones (GTC) del Instituto de Investigación en Ingeniería de Aragón (I3A) de la Universidad de Zaragoza.
¿Qué es?
La solución que aportamos desde ViVoLab es la utilización de un esquema distribuido para el reconocimiento y síntesis de voz.
El sistema sigue una arquitectura cliente-servidor, en la que el cliente es un applet (módulo o programa realizado en java, y que se puede incrustar en cualquier página web). Dicho cliente se ejecutará en cualquier navegador web, siempre que éste tenga habilitado java. El cliente de reconocimiento de voz realiza las funciones de adquisición de audio, parametrización (MFCC), y compresión de los parámetros acústicos (DVQ) para reducir el ancho de banda de envío hasta 2.1 Kbps. Otras funciones del applet son la captura de gramáticas, codificación, y envío al servidor, así como la gestión de una máquina de estados muy simple y configurable. El cliente de síntesis de voz realiza la adquisición del texto a convertir, su envío al servicio web y la descodificación de la señal de voz enviada por el servicio web de síntesis. Para la codificación y descodificación se ha utilizado el software speex con una calidad de 16 kHz y transmisión a 12 kbs.
Ayuda
Control del Sistema de Reconocimiento Automático del Habla
![]() Icono del Applet de control con los sistemas de reconocimiento (micrófono) y síntesis de voz (burbuja) desconectados. Entre ambos iconos se sitúa el medidor de nivel de señal en el micrófono. En azul, nivel bajo, en verde, nivel correcto, en rojo, saturación.
Icono del Applet de control con los sistemas de reconocimiento (micrófono) y síntesis de voz (burbuja) desconectados. Entre ambos iconos se sitúa el medidor de nivel de señal en el micrófono. En azul, nivel bajo, en verde, nivel correcto, en rojo, saturación.
![]() Pulsando sobre el icono del micrófono ponemos en conexión el applet-cliente de la página web con el servidor remoto de reconocimiento. Mientras el icono del micrófono está en naranja el cliente está realizando la conexión con el servidor remoto. Una vez establecida la conexión el sistema, según la configuración, puede pasar a estado de espera activa (icono amarillo) o a estado de reconocimiento (icono verde).
Pulsando sobre el icono del micrófono ponemos en conexión el applet-cliente de la página web con el servidor remoto de reconocimiento. Mientras el icono del micrófono está en naranja el cliente está realizando la conexión con el servidor remoto. Una vez establecida la conexión el sistema, según la configuración, puede pasar a estado de espera activa (icono amarillo) o a estado de reconocimiento (icono verde).
![]()
Si por configuración se ha elegido que el sistema se inicie en espera activa, una vez conectado con el servidor, el icono pasa a color amarillo y se queda a la espera de que el usuario diga la frase de activación "escucha mi voz". Si transcurridos 20 segundos, el usuario no dice nada, el sistema pasa a estado de desconexión.
![]() Una vez activado el reconocedor con la frase de activación o por configuración inicial, el icono pasa a color verde y se queda comienza a reconocer la señal que capta el micrófono. El sistema se queda en este estado durante un máximo de 20 segundos. Si el usuario no dice nada, pasa a estado de desconexión. El medidor de nivel de sonido debe situarse en color verde para un nivel adecuado.
Una vez activado el reconocedor con la frase de activación o por configuración inicial, el icono pasa a color verde y se queda comienza a reconocer la señal que capta el micrófono. El sistema se queda en este estado durante un máximo de 20 segundos. Si el usuario no dice nada, pasa a estado de desconexión. El medidor de nivel de sonido debe situarse en color verde para un nivel adecuado.
![]() Si el medidor de nivel de sonido se queda en la zona azul, quiere decir que el nivel no es suficiente y hay que amplificar mas la señal de voz con el controlador de grabación del sistema operativo. Con el micrófono seleccionado, ajustar el nivel para que cuando se habla, la barra de nivel se mueva en la zona de color verde, sin llegar a ponerse roja.
Si el medidor de nivel de sonido se queda en la zona azul, quiere decir que el nivel no es suficiente y hay que amplificar mas la señal de voz con el controlador de grabación del sistema operativo. Con el micrófono seleccionado, ajustar el nivel para que cuando se habla, la barra de nivel se mueva en la zona de color verde, sin llegar a ponerse roja.
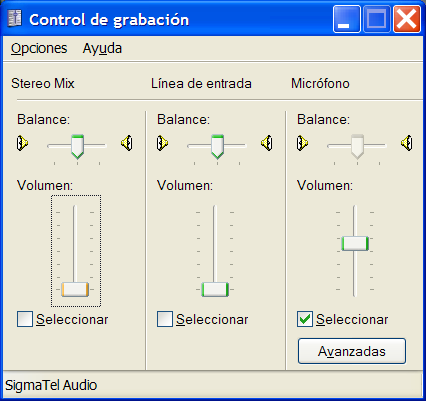
Control del conversor texto-voz
![]() Pulsando sobre el icono de la burbuja verde se activa (fondo verde) o se desactiva (fondo rojo) la conexión con el webservice de síntesis de voz. Ajustar el nivel de salida de audio de forma conveniente.
Pulsando sobre el icono de la burbuja verde se activa (fondo verde) o se desactiva (fondo rojo) la conexión con el webservice de síntesis de voz. Ajustar el nivel de salida de audio de forma conveniente.
Como instalar el applet
Para utilizar la funcionalidad de navegación por voz para hacer la web accesible contactar con vivolab.
Descripción de los parámetros
URLgrammar
Dirección URL con la gramática en formato jsgf (Java Speech Grammar Format).
Un ejemplo sencillo:
#JSGF V1.0 ISO8859-1 es;
grammar fsg.reproductor;
public <reproductor> =
play {play}|
pausa {pausa}|
stop {stop}|
subirvolumen {subirvolumen}|
bajarvolumen {bajarvolumen} |
(navegar a google) {http://www.google.es} |
(navegar a marca) {http://www.marca.com} |
(navegar a invertia) {http://www.invertia.com} |
(navegar a el mundo) {http://www.elmundo.es} |
(navegar a el pais) {http://www.elpais.es} |
(navegar a reconocimiento de voz) {http://physionet.cps.unizar.es/~eduardo/sp/index.html} ;
El applet lo que recibe siempre del backend el tag de la palabra reconocida (lo que va entre {tag} en la gramática). Este tag puede ser:
1. una dirección web, para ello mira si el tag comienza en los caracteres http://, en cuyo caso automáticamente navega a la página web indicada.
2. una acción, el applet realiza una llamada a una función javascript con el nombre del tag y sin pasar ningún argumento. De esta forma, en una página web se pueden realizar un control por voz sobre un reproductor de música (detenerlo, iniciar una reproducción, subir el volumen), o sobre cualquier objeto dentro de ella, por medio de llamadas javascript.
host
host con el backend de reconocimiento y conversión texto-voz. En estos momentos se encuentra disponible el siguiente servidor: gtc3pc23.cps.unizar.es
NOTA: este servidor puede desconectarse en cualquier momento
port
puerto de comunicación (por defecto 22229)
INI
estado inicial del reconocedor:
"conectado" .. El reconocedor se inicia directamente al cargar la página web con la gramática de control de la misma definida en URLgrammar.
"espera" .. El reconocedor se inicia en estado de espera. En este estado el reconocedor espera la activación mediante una palabra de activación definida en la gramática indicada en el parámetro INIURLgrammar
"desconectado" .. El reconocedor se inicia en estado desconectado y es preciso pulsar en el applet para activarlo
INIURLgrammar
Si se desea definir una palabra/frase de activación para el estado de espera, se indica mediante esta gramática.
Esta gramática tiene que ser de la forma
#JSGF V0.1 ISO8859-1 es;
grammar fsg.esperar;
public <esperar> = <fon>* [<keyword>] ;
<keyword> = (palabras o frase clave) {listen};
<fon> = /0.1/ B | /0.1/ D | /0.1/ G | /0.1/ J | /0.1/ L | /0.1/ T | /0.1/ f | /0.1/ j | /0.1/ k | /0.1/ l | /0.1/ m | /0.1/ n | /0.1/ p | /0.1/ r | /0.1/ rr | /0.1/ s |/0.1/ t | /0.1/ tS | /0.1/ w | /0.1/ x | /0.1/ aa | /0.1/ ee |/0.1/ ii | /0.1/ oo | /0.1/ uu;
sinte_speaker
Este parámetro indica el nombre de la voz que se utilizará por defecto para realizar la conversión texto-voz (en estos momentos están disponibles las voces Jorge y Carmen. (En breve estarán disponibles las voces Michel y Ana)
sinte_service
URL con el servicio de conversión texto-voz. En estos momentos únicamente disponible en:
http://gtc3pc23.cps.unizar.es:8080/tts_servlet_unizar_cache_codec/sinte
sinte_codec
El resultado de la síntesis de voz se envía a la página web codificada con Speex con distintas calidades. value="3" es el recomendado con una tasa de transmisión promedio de 12 kbps.
Sinte_INI
on ... se inicia el conversor texto-voz al cargar la página
off ... se inicia con el conversor texto-voz desconectado. Es preciso pulsar el icono para activarlo.
Funciones del applet disponibles desde JavaScript
UZSetBeep
UZSetIniColor
UZStartRecoGrammar
UZStartRecoGrammarText
UZSinte
UZStopApplet
Variables del applet disponibles desde JavaScript
UZtags
UZresults
UZerrorstr ; UZerrorcode
Funciones de Javascript llamadas desde el applet
function recopushini()
reco button pushed for start
function recopushini(){
document.vivoreco.UZSetBeep(0); //beeps desactivados
document.vivoreco.UZSetIniColor(1); //color amarillo
document.vivoreco.UZStartRecoGrammar
("http://www.vivolab.es/demos/dsr/espera_ar2_grammar_applet.jsgf");
}
function recopushend()
end of connection
function recoend()
end of recognition
function recoend(){
//Check results
switch (n){
case 1:
if (document.vivoreco.UZtags == "listen"){
document.vivoreco.UZSinte("Ya he despertado", "Carmen");
document.vivoreco.UZSetBeep(1); //beeps activados
document.vivoreco.UZSetIniColor(0); //color verde
n = 3;
}
break;
case 2:
document.vivoreco.UZSinte(document.vivoreco.UZresults, "Carmen");
n = 3;
break;
case 3:
document.vivoreco.UZSinte(document.vivoreco.UZresults, "Jorge");
n = 2;
break;
}
//Action new states
switch (n){
case 1:
document.vivoreco.UZSinte("Estoy dormida", "Carmen");
document.vivoreco.UZStartRecoGrammar
("http://www.vivolab.es/demos/dsr/espera_ar2_grammar_applet.jsgf");
break;
case 2:
document.vivoreco.UZSinte("Gramatica de personal de vivolab", "Carmen");
document.vivoreco.UZStartRecoGrammar
("http://www.vivolab.es/demos/dsr/personal_grammar_applet.jsgf");
break;
case 3:
document.vivoreco.UZSinte ("Gramatica de navegacion de Eduardo", "Carmen");
document.vivoreco.UZStartRecoGrammar ("http://physionet.cps.unizar.es/~eduardo/grammars/navegar-web-eduardo.jsgf");
break;
case 4:
document.vivoreco.UZSinte("Ya he realizado 5 reconocimientos, voy a desconectar", "Jorge");
document.vivoreco.UZStopApplet();
break;
}
}
function recoerror()
reco errors
function recoerror(){
alert("Error: " + document.vivoreco.UZerrorstr);
}
Funciones de Javascript disponibles
function cerrarventanaprincipal()
se utiliza para ....
function cerrarventana()
se utiliza para cerrar una ventana secundaria y activar el applet en la ventana principal
function parar_applet()
Desconecta el applet de reconocimiento de voz
function pararhijo_lanzarpadre()
function sintetiza(frase,locutor)
function stop_sinte()
Consejos de uso
Para un correcto funcionamiento del sistema se recomienda el uso de cascos con micrófono. Si se utilizan los altavoces del ordenador y el micrófono incorporado en el ordenador (p.e. en los portátiles), se corre el riesgo de realimentación acústica entre el altavoz y el micrófono que puede perturbar las prestaciones del sistema de reconocimiento.
Navegación web por voz
|
¿Qué puedo sintetizar? Pon el ratón sobre un enlace y el sistema lo leerá ¿Qué puedo decir?
Con el icono del micrófono en amarillo debes decir "escucha mi voz" para activar el reconocedor Selección locutores. > Activo: |